PostgreSQL. Установка и настройка
05.07.2024
Теги: БазаДанных • Клиент • Конфигурация • Настройка • Пользователь • Сервер • Установка
PostgreSQL — объектно-реляционная система управления базами данных. PostgreSQL базируется на языке SQL, отличается гибкостью и надежностью и поддерживает множество возможностей. Чаще всего PostgreSQL используется для сложных проектов, где требуется работа со сложными структурами данных, которые могут не поддерживаться обычными СУБД.
Установка сервера
В самом простом случае можно установить PostgreSQL из репозитория Ubuntu
$ sudo apt install postgresql
Чтобы установить самую последнюю версию PostgreSQL или наоборот, какую-то старую версию — нужно добавить репозиторий. Пакеты в репозитории подписаны закрытым OpenPGP ключом репозитория, а чтобы проверить их подлинность, потребуется открытый OpenPGP ключ. Каждый репозиторий доверяет только собственному ключу, а сами ключи помещаются в специальное хранилище /usr/share/keyrings, к которому имеет доступ только суперпользователь.
Ключ может быть в двух форматах — текстовом (расширение файла .asc) и бинарном (расширение файла .gpg). Текстовые ключи наиболее распространены, так как этот формат более удобен при передаче. Но ключ в хранилище должны быть в бинарном формате, то есть, потребуется преобразование.
Скачать ключ, преобразовать в бинарный формат и записать в хранилище
$ curl -s https://www.postgresql.org/media/keys/ACCC4CF8.asc | gpg --dearmor | \ > sudo tee /usr/share/keyrings/postgresql.org.gpg > /dev/null
Теперь нужно создать файл .list в директории /etc/apt/sources.list.d
$ echo "deb [arch=amd64 signed-by=/usr/share/keyrings/postgresql.org.gpg] \ > https://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" | \ > sudo tee /etc/apt/sources.list.d/postgresql.org.list > /dev/null
Теперь получим данные о новых, доступных к установке, пакетах
$ sudo apt update
Посмотрим, какая последняя версия доступна для установки
$ apt-cache policy postgresql postgresql: Установлен: (отсутствует) Кандидат: 16+261.pgdg24.04+1 Таблица версий: 16+261.pgdg24.04+1 500 500 https://apt.postgresql.org/pub/repos/apt noble-pgdg/main amd64 Packages 16+257build1 500 500 http://ru.archive.ubuntu.com/ubuntu noble/main amd64 Packages
Посмотрим, какие вообще версии доступны для установки
$ apt-cache pkgnames | egrep 'postgresql-[0-9]+$' postgresql-10 postgresql-11 postgresql-12 postgresql-13 postgresql-14 postgresql-15 postgresql-16
Устанавливаем последнюю версию PostgreSQL
$ sudo apt install postgresql
Проверяем работу сервера PostgreSQL
$ systemctl status postgresql.service ● postgresql.service - PostgreSQL RDBMS Loaded: loaded (/usr/lib/systemd/system/postgresql.service; enabled; preset: enabled) Active: active (exited) since Fri 2024-07-05 11:21:30 UTC; 44min ago Main PID: 9793 (code=exited, status=0/SUCCESS) CPU: 5ms июл 05 11:21:30 ubuntu24-server systemd[1]: Starting postgresql.service - PostgreSQL RDBMS... июл 05 11:21:30 ubuntu24-server systemd[1]: Finished postgresql.service - PostgreSQL RDBMS.
При установке будет автоматически создан пользователь Linux postgres и пользователь кластера postgres, под которым можно будет начать работу с PostgreSQL. У этого пользователя Linux нет пароля, но для пользователя root это не имеет значения. Пользователь кластера postgres является суперпользователем, его права практически не ограничены.
Кластером называют набор баз данных, управляемых одним экземпляром работающего сервера. После установки кластер будет содержать базу данных с именем postgres, предназначенную для использования утилитами, пользователями и сторонними приложениями. Сам сервер баз данных не требует наличия этой базы, но многие внешние вспомогательные программы рассчитывают на её существование. При инициализации в кластере создаются ещё две базы — template1 и template0. Они применяются впоследствии в качестве шаблонов создаваемых баз данных; использовать их в качестве рабочих не следует.
Подключение к серверу
Как отмечалось выше, во время установки были автоматически созданы пользователь ОС postgres и роль БД postgres. Для начала работы нужно войти под этим пользователем и запустить клиент psql.
$ sudo su -l postgres [sudo] password for evgeniy: пароль $ whoami postgres $ psql psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > help Вы используете psql - интерфейс командной строки к PostgreSQL. Азы: \copyright - условия распространения \h - справка по операторам SQL \? - справка по командам psql \g или ; в конце строки - выполнение запроса \q - выход > \q
Для каждой созданной роли PostgreSQL предполагает наличие базы данных с таким же именем и по умолчанию подключается именно к ней. Так что имеет смысл создавать новую роль для каждой новой базы. Кроме того, если имя роли совпадает с именем пользователя Linux, подключение к БД также упрощается.
Терминальный клиент
Утилита psql — это терминальный клиент для работы с PostgreSQL. Позволяет интерактивно вводить запросы, передавать их в PostgreSQL и видеть результаты. Также запросы могут быть получены из файла или из аргументов командной строки. Кроме того, psql предоставляет ряд метакоманд и различные возможности, подобные тем, что имеются у командных оболочек, для облегчения написания скриптов и автоматизации широкого спектра задач.
$ psql --help psql - это интерактивный терминал PostgreSQL. Использование: psql [ПАРАМЕТР]... [БД [ПОЛЬЗОВАТЕЛЬ]] Общие параметры: -c, --command=КОМАНДА выполнить одну команду (SQL или внутреннюю) и выйти -d, --dbname=БД имя подключаемой базы данных (по умолчанию "postgres") -f, --file=ИМЯ_ФАЙЛА выполнить команды из файла и выйти -l, --list вывести список баз данных и выйти -v, --set=, --variable=ИМЯ=ЗНАЧЕНИЕ присвоить переменной psql ИМЯ заданное ЗНАЧЕНИЕ (например: -v ON_ERROR_STOP=1) -V, --version показать версию и выйти -X, --no-psqlrc игнорировать файл параметров запуска (~/.psqlrc) -1 ("один"), --single-transaction выполнить как одну транзакцию (в неинтерактивном режиме) -?, --help[=options] показать эту справку и выйти --help=commands перечислить команды с \ и выйти --help=variables перечислить специальные переменные и выйти Параметры ввода/вывода: -a, --echo-all отображать все команды из скрипта -b, --echo-errors отображать команды с ошибками -e, --echo-queries отображать команды, отправляемые серверу -E, --echo-hidden выводить запросы, порождённые внутренними командами -L, --log-file=ИМЯ_ФАЙЛА сохранять протокол работы в файл -n, --no-readline отключить редактор командной строки readline -o, --output=ИМЯ_ФАЙЛА направить результаты запроса в файл (или канал |) -q, --quiet показывать только результаты запросов, без сообщений -s, --single-step пошаговый режим (подтверждение каждого запроса) -S, --single-line однострочный режим (конец строки завершает команду) Параметры вывода: -A, --no-align режим вывода невыровненной таблицы --csv режим вывода в формате CSV (значения, разделённые запятыми) -F, --field-separator=СТРОКА разделителей полей при невыровненном выводе (по умолчанию: "|") -H, --html вывод таблицы в формате HTML -P, --pset=ПАР[=ЗНАЧ] определить параметр печати ПАР (с заданным ЗНАЧЕНИЕМ) (см. описание \pset) -R, --record-separator=СТРОКА разделитель записей при невыровненном выводе (по умолчанию: новая строка) -t, --tuples-only выводить только кортежи -T, --table-attr=ТЕКСТ установить атрибуты HTML-таблицы (width, border) -x, --expanded включить развёрнутый вывод таблицы -z, --field-separator-zero сделать разделителем полей при невыровненном выводе нулевой байт -0, --record-separator-zero сделать разделителем записей при невыровненном нулевой байт Параметры подключения: -h, --host=ИМЯ имя сервера баз данных или каталог сокетов (по умолчанию: "/var/run/postgresql") -p, --port=ПОРТ порт сервера баз данных (по умолчанию: "5432") -U, --username=ИМЯ имя пользователя (по умолчанию: "postgres") -w, --no-password не запрашивать пароль -W, --password запрашивать пароль всегда (обычно не требуется) Чтобы узнать больше, введите "\?" (список внутренних команд) или "\help" (справка по операторам SQL) в psql, либо обратитесь к разделу psql в документации PostgreSQL. Об ошибках сообщайте по адресу <pgsql-bugs@lists.postgresql.org>. Домашняя страница PostgreSQL: <https://www.postgresql.org/>
Подробное описание терминального клиента можно найти в документации здесь. После подключения к серверу базы данных — можно получить список команд psql и операторов SQL. Кроме того, можно получить подробную справку по каждому оператору SQL.
$ psql psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > help Вы используете psql - интерфейс командной строки к PostgreSQL. Азы: \copyright - условия распространения \h - справка по операторам SQL \? - справка по командам psql \g или ; в конце строки - выполнение запроса \q - выход > \q
Команды клиента psql
Команды можно выполнять после подключения к серверу. Все рассмотреть затруднительно, поэтому лишь наиболее часто используемые.
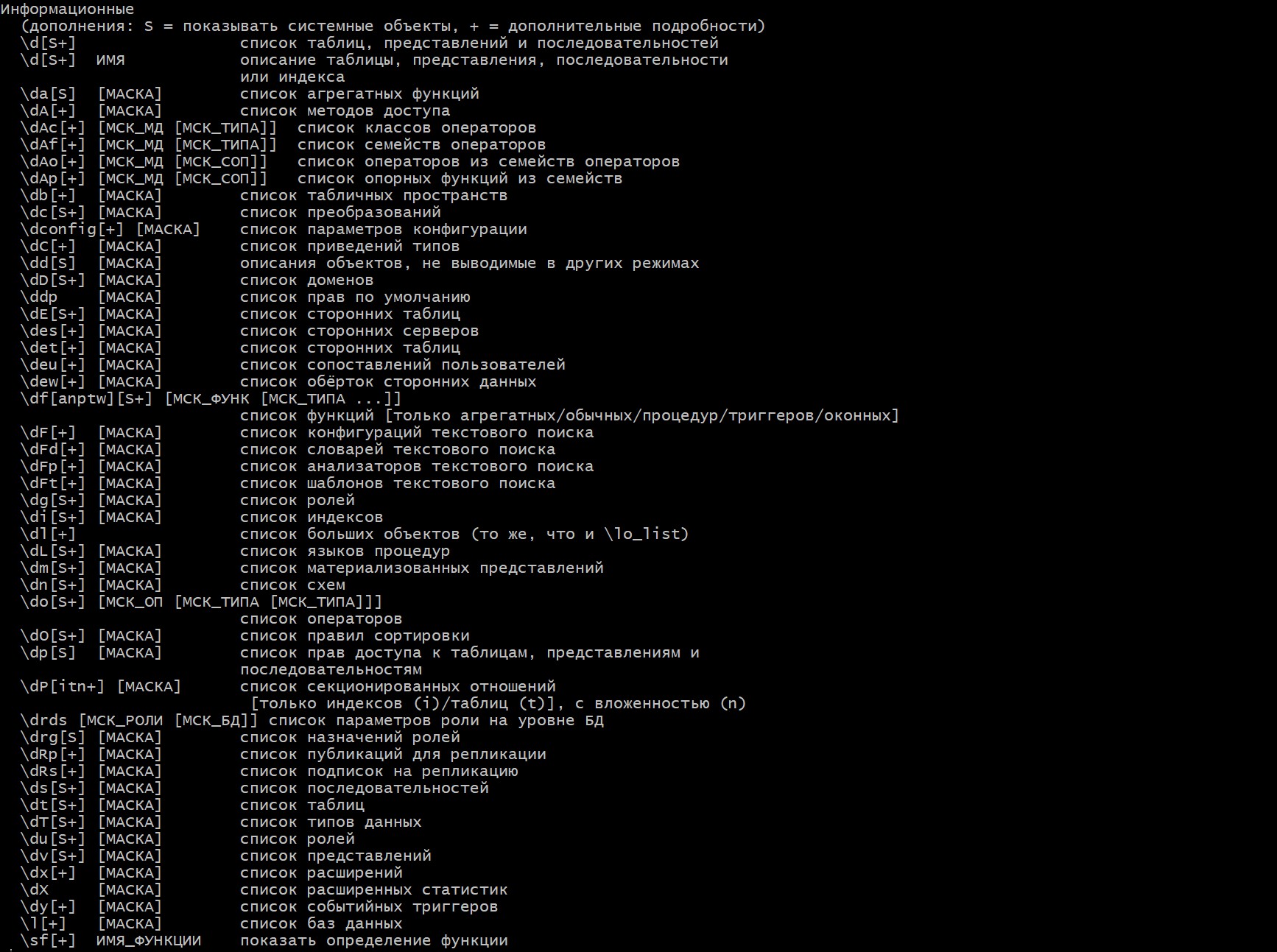
\l— список доступных баз данных\c name— подключиться к базе данныхnameпод текущим пользователем\c - user— подключиться к текущей базе данных под пользователемuser\c name user— подключиться к базе данныхnameпод пользователемuser\d— список таблиц, представлений и последовательностей\d name— описание таблицы, представления, последовательности\dt— список таблиц\dv— список представлений\ds— список последовательностей\du— список пользователей (ролей)\dp— список прав доступа к таблицам, представлениям и последовательностям\password [user]— изменить пароль пользователяuserили текущего пользователя
Типовой сценарий
Создадим базу данных, роль для работы с этой базой и предоставим все права на базу для этой роли. Для этого подключаемся с серверу как пользователь postgres и выполняем запросы.
$ whoami postgres $ psql
CREATE DATABASE test; CREATE ROLE test WITH LOGIN PASSWORD 'qwe123'; -- все права пользователю test на базу данных test GRANT ALL PRIVILEGES ON DATABASE test TO test;
Потом подключаемся как пользователь postgres к новой базе данных test и выполняем еще один запрос.
$ whoami postgres $ psql --dbname=test
-- права для роли test на схему public внутри базы test GRANT ALL PRIVILEGES ON SCHEMA public TO test;
Обратите внимание, что права на схему public пользователю test выдаются после подключения к базе данных test. Схема public существует внутри любой базы данных, ее владельцем является пользователь postgres. Изначально при подключении мы не указываем базу данных, в этом случае подключение идет к базе данных postgres. Но для выдачи прав на схему public внутри базы test — нужно подключиться к базе test. Иначе мы выдадим права на схему public внутри базы данных postgres — а это совсем не то, что нужно.
Мы выдаем пользователю test все права на базу данных test, в том числе право CREATE, которое позволяет создавать схемы. Это дает возможность пользователю test создать схему, например test_schema, на которую у него будет все права, поскольку он является ее владельцем. И далее создавать таблицы внутри этой схемы — тогда права на схему public пользователю test будут не нужны.
$ psql --username=test --dbname=test --host=localhost
CREATE SCHEMA test_schema; CREATE TABLE test_schema.test_table (id serial PRIMARY KEY, content text);
Пользователи (роли)
Вместо привычного понятия пользователей, PostgreSQL использует концепцию ролей. В зависимости от настройки, роль можно рассматривать как пользователя кластера или как группу пользователей. Роли могут владеть объектами кластера (базы данных, таблицы) и выдавать другим ролям разрешения на доступ к этим объектам. Также можно предоставить одной роли членство в другой роли (схоже с добавлением пользователя в группу), чтобы одна роль могла использовать привилегии другой. Обычно роль, для которой разрешает вход, считается пользователем (user), а роль, которой не разрешен вход — группой (group).
1. Создание новой роли
Создать новую роль можно с помощью команды createuser или оператора CREATE ROLE.
1.1. Команда createuser
Создать роль из консоли операционной системы (не psql) можно с помощью команды createuser.
$ createuser --help createuser создаёт роль пользователя PostgreSQL. Использование: createuser [ПАРАМЕТР]... [ИМЯ_РОЛИ] Параметры: -a, --with-admin=РОЛЬ заданная роль будет членом новой роли с привилегией ADMIN -c, --connection-limit=N предел подключений для роли (по умолчанию предела нет) -d, --createdb роль с правом создания баз данных -D, --no-createdb роль без права создания баз данных (по умолчанию) -e, --echo отображать команды, отправляемые серверу -g, --member-of=РОЛЬ новая роль будет членом заданной роли --role=РОЛЬ (устаревшая альтернатива --member-of) -i, --inherit роль наследует права ролей (групп), в которые она включена (по умолчанию) -I, --no-inherit роль не наследует права -l, --login роль с правом подключения к серверу (по умолчанию) -L, --no-login роль без права подключения -m, --with-member=РОЛЬ заданная роль будет членом новой роли -P, --pwprompt назначить пароль новой роли -r, --createrole роль с правом создания других ролей -R, --no-createrole роль без права создания ролей (по умолчанию) -s, --superuser роль с полномочиями суперпользователя -S, --no-superuser роль без полномочий суперпользователя (по умолчанию) -v, --valid-until=ДАТА_ВРЕМЯ дата и время истечения срока пароля для роли -V, --version показать версию и выйти --interactive запрашивать отсутствующие атрибуты и имя роли, а не использовать значения по умолчанию --bypassrls роль не будет подчиняться политикам защиты на уровне строк (RLS) --no-bypassrls роль будет подчиняться политикам защиты на уровне строк (по умолчанию) --replication роль может инициировать репликацию --no-replication роль не может инициировать репликацию (по умолчанию) -?, --help показать эту справку и выйти Параметры подключения: -h, --host=ИМЯ имя сервера баз данных или каталог сокетов -p, --port=ПОРТ порт сервера баз данных -U, --username=ИМЯ имя пользователя для выполнения операции (но не имя новой роли) -w, --no-password не запрашивать пароль -W, --password запросить пароль Об ошибках сообщайте по адресу <pgsql-bugs@lists.postgresql.org>. Домашняя страница PostgreSQL: <https://www.postgresql.org/>
Давайте создим новую роль blog
$ whoami postgres $ createuser --pwprompt --interactive Введите имя новой роли: blog Введите пароль для новой роли: qwerty Повторите его: qwerty Должна ли новая роль иметь полномочия суперпользователя? (y - да/n - нет) n Новая роль должна иметь право создавать базы данных? (y - да/n - нет) n Новая роль должна иметь право создавать другие роли? (y - да/n - нет) n
Опция pwprompt позволит сразу задать пароль пользователю, опция interactive запустит интерактивный режим для указания дополнительных параметров. По умолчанию, если не использовать опцию no-login, будет создана роль с правом аутентификации — то есть, с привилегией LOGIN.
1.2. Оператор CREATE ROLE
Второй способ создания роли — подключиться с серверу PostgreSQL и выполнить CREATE ROLE. При использовании этого операторв без дополнительных опций пользователь будет создан без каких-либо привилегий, поэтому желательно сразу при создании роли указывать нужные привилегии.
$ whoami postgres $ psql psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > CREATE ROLE shop WITH LOGIN CREATEDB CREATEROLE; # создание роли (оператор SQL) CREATE ROLE > \password shop # пароль для shop (команда psql) Введите новый пароль для пользователя "shop": 123456 Повторите его: 123456 > \du # список ролей (команда psql) Имя роли | Атрибуты ----------+------------------------------------------------------------------------- blog | postgres | Суперпользователь, Создаёт роли, Создаёт БД, Репликация, Пропускать RLS shop | Создаёт роли, Создаёт БД > \q
Роль blog не имеет привилегий CREATEDB и CREATEROLE, только LOGIN. Для нее потребуется создать базу данных, создать ее самостоятельно эта роль не может. С другой стороны, роль shop имеет привилегии LOGIN, CREATEDB, CREATEROLE — может сама создавать базы данных и новые роли.
2. Изменить пароль
Можно использовать команду клиента \password [user] или использовать оператор ALTER ROLE. Обычный пользователь может изменить только свой пароль, суперпользователь postgres может изменить пароль любого пользователя.
$ whoami postgres $ psql psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > \password test Введите новый пароль для пользователя "test": Повторите его: > ALTER ROLE test WITH PASSWORD 'qwerty'; ALTER ROLE > \q
3. Как удалить роль
Удалить роль можно с помощью команды dropuser или оператора DROP ROLE.
$ whoami postgres $ dropuser test
$ whoami postgres $ psql psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > DROP ROLE test; DROP ROLE > \q
test не приводит к удалению базы данных test.
Вместо удаления можно ограничить роль в правах
REVOKE ALL PRIVILEGES ON ALL TABLES IN SCHEMA public FROM test;
4. Неявная роль public
Кластер PostgreSQL имеет неявную роль public, которую нельзя удалить. Все остальные роли всегда имеют членство в public по умолчанию и наследуют все привилегии, присвоенные этой роли. Если ничего не менялось, привилегии public следующие — CONNECT, TEMPORARY, EXECUTE (функции и процедуры), USAGE (домены, языки и типы).
Здесь важно заметить, что роль public всегда имеет привилегию CONNECT, предоставляемую по умолчанию и служащую для удобства разрешения всем ролям подключаться к вновь созданной базе данных. Без привилегии подключения к базе данных никакая из созданных нами ролей не могла бы что-либо сделать.
Чтобы открыть соединение с кластером PostgreSQL, пользователю нужно сначала пройти аутентификацию (предоставив учетные данные для роли WITH LOGIN), а затем проверку на право подключения к базе данных. Поскольку каждой роли предоставлено участие в роли public, и эта роль имеет привилегию CONNECT по умолчанию, все роли, которые могут пройти аутентификацию, имеют также разрешение на CONNECT.
5. Создание группы
Группа — это роль без права входа. В дальнейшем можно будет назначить этой роли привилегии и включать в нее другие роли. Другие роли будут наследовать привилегии групповой роли, если они были созданы с атрибутом INHERIT (по умолчанию).
CREATE ROLE dev_group WITH NOLOGIN;
Предоставим привилегии для работы со схемой public
-- предварительно требуется подключиться к нужной базе данных GRANT ALL PRIVILEGES ON SCHEMA public TO dev_group;
Создадим новую роль dev_two и сразу добавим ее в группу dev_group
-- новая роль разработчика dev_two сразу добавляется в группу dev_group CREATE ROLE dev_two WITH LOGIN PASSWORD 'qwerty' IN ROLE dev_group;
Чтобы добавить существующую роль в существующую групповую роль
-- добавляем пользователя dev_one в группу dev_group GRANT dev_group TO dev_one;
Чтобы удалить роль из группы (и тем самым лишить привилегий)
-- удаляем пользователя dev_one из группы dev_group REVOKE dev_group FROM dev_one;
При создании групповой роли можно сразу добавить в нее существующие роли
-- роли dev_one, dev_two добавляются в группу dev_group CREATE ROLE dev_group WITH NOLOGIN ROLE dev_one, dev_two;
Включение в группу с передачей права управления
-- теперь dev_admin может сам добавлять роли в группу dev_group GRANT dev_group TO dev_admin WITH ADMIN OPTION;
-- этот оператор выполняется от имени пользователя dev_admin; -- роли dev_one и dev_two добавляются в группу dev_group с -- правом передачи управления групповой ролью dev_group GRANT dev_group TO dev_one WITH ADMIN OPTION; GRANT dev_group TO dev_two WITH ADMIN OPTION;
Отозвать право передачи управления можно так
REVOKE ADMIN OPTION FOR dev_group FROM dev_admin;
Если роль с правом передачи управления уже успела передать это право другим ролям — можно отозвать это право у всех сразу.
REVOKE ADMIN OPTION FOR dev_group FROM dev_admin CASCADE;
6. Оператор SET ROLE
Оператор меняет текущую роль на другая_роль в текущем сеансе. После SET ROLE, права доступа проверяются так, как если бы сеанс изначально был установлен от имени другая_роль. Указывая другая_роль, текущий пользователь должен являться членом этой роли.
SET [SESSION|LOCAL] ROLE другая_роль SET [SESSION|LOCAL] ROLE NONE RESET ROLE
Если используется SESSION (по умолчанию) — оператор SET ROLE будет действовать до конца сеанса или до оператора RESET ROLE или до оператора SET ROLE NONE. Если используется LOCAL — оператор SET ROLE будет действовать только в рамках текущей транзакции. Проверить текущую роль можно с помощью функций session_role и current_role. Функция session_role возвращает имя пользователя, который начал текущий сеанс. Функция current_role возвращает текущее имя пользователя после выполнения SET ROLE.
Работа с базой данных
1. Создание базы данных
Создать базу данных можно с помощью команды createdb или оператора CREATE DATABASE.
$ whoami postgres $ createdb blog
$ whoami postgres $ psql psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > CREATE DATABASE shop; # создание базы данных (оператор SQL) CREATE DATABASE > \l # список баз данных (команда psql) Имя | Владелец | Кодировка | Провайдер … | LC_COLLATE | LC_CTYPE | Локаль … | Правила … | Права доступа -----------+----------+-----------+-------------+-------------+-------------+----------+-----------+----------------------- blog | postgres | UTF8 | libc | ru_RU.UTF-8 | ru_RU.UTF-8 | | | postgres | postgres | UTF8 | libc | ru_RU.UTF-8 | ru_RU.UTF-8 | | | shop | postgres | UTF8 | libc | ru_RU.UTF-8 | ru_RU.UTF-8 | | | template0 | postgres | UTF8 | libc | ru_RU.UTF-8 | ru_RU.UTF-8 | | | =c/postgres + | | | | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | libc | ru_RU.UTF-8 | ru_RU.UTF-8 | | | =c/postgres + | | | | | | | | postgres=CTc/postgres > \q
Когда в кластере создаётся объект, ему назначается владелец. Владельцем обычно становится роль, от имени которой был выполнен оператор создания. Для большинства типов объектов только владелец или суперпользователь может делать с объектом всё, что угодно. Чтобы разрешить использовать его другим ролям, нужно дать им права.
В столбце «Права Доступа» показаны права пользователей на базы данных с использованием сокращений. Значение test=CTc/postgres означает, что пользователю test были выданы права CTc — это CREATE, TEMPORARY, CONNECT. А выдал эти права пользователь postgres.
public.
2. Удаление базы данных
Удалить базу данных можно с помощью команды dropdb или оператора DROP DATABASE.
$ whoami postgres $ dropdb test
$ whoami postgres $ psql psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > DROP DATABASE test; DROP DATABASE > \q
3. Подключение к базе данных
По умолчанию, без дополнительных опций, клиент psql пытается подключиться от имени текущего пользователя к одноименной базе. Поэтому, если имя пользователя Linux совпадает с именем роли и именем базы данных, достаточно выполнить psql.
$ whoami postgres $ psql psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > \conninfo Вы подключены к базе данных "postgres" как пользователь "postgres" через сокет в "/var/run/postgresql", порт "5432". > \q
Если имя базы данных, к которой нужно подключиться, отличается от имени текущего пользователя Linux — нужно передать имя базы
$ whoami postgres $ psql --dbname=blog psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > \conninfo Вы подключены к базе данных "blog" как пользователь "postgres" через сокет в "/var/run/postgresql", порт "5432". > \q
Если отличается имя базы данных и имя текущего пользователя от роли PostgreSQL — нужно передать имя базы и роль пользователя
$ whoami postgres $ psql --dbname=blog --username=blog --host=localhost Пароль пользователя blog: qwerty psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > \conninfo Вы подключены к базе данных "blog" как пользователь "blog" (сервер "localhost": адрес "127.0.0.1", порт "5432"). SSL-соединение (протокол: TLSv1.3, шифр: TLS_AES_256_GCM_SHA384, сжатие: выкл.) > \q
К кластеру можно подключиться через unix-сокет или по сети. Пользователь postgres может подключаться только через unix-сокет, пользователи blog и shop — только по сети, это задается в файле конфигурации pg_hba.conf. Чтобы подключиться по сети — нужно указать хост и порт (по умолчанию 5432).
4. Изменение владельца БД
Изменить владельца базы данных можно с помощью оператора ALTER DATABASE
ALTER DATABASE база_данных OWNER TO новый_владелец
Но у всех объектов этой базы данных (включая таблицы) останется прежний владелец. Чтобы изменить владельца объектов — нужно использовать REASSIGN OWNED. Все объекты в текущей базе данных и все базы данных, принадлежащие старой_роли, станут принадлежать новой_роли.
REASSIGN OWNED BY старая_роль TO новая_роль
REASSIGN OWNED, когда исходная роль — postgres, это может привести к фатальным последствям. Оператор обновит все объекты, назначив нового владельца, включая системные ресурсы.
5. Создание таблицы
У нас есть пользователь blog и база данных blog. Но если мы попытаемся под пользователем blog создать таблицу в базе blog, то получим ошибку «permission denied for schema public» — потому что у пользователя blog нет прав на использование схемы public внутри базы blog.
Схемы в PostgreSQL — это пространства имен для таблиц, предназначенные для логического разделения объектов и предотвращения конфликтов имен. Проще говоря, это некие контейнеры, в которые можно помещать таблицы.
Существуют схемы по умолчанию, созданные PostgreSQL. Одна из таких схем называется public. Именно в нее будут попадать все созданные нами таблицы по умолчанию, если мы не укажем какую-то другую схему.
Нужно подключиться к базе данных blog под пользователем postgres и предоставить пользователю blog право использовать схему public.
$ whoami postgres $ psql --dbname=blog psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > GRANT ALL PRIVILEGES ON SCHEMA public TO blog; GRANT > \q
Теперь подключаемся к базе данных blog под пользователем blog — и создаем таблицы articles и authors.
$ psql --dbname=blog --username=blog --host=localhost psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > CREATE TABLE articles (id serial PRIMARY KEY, title varchar(100), content text); CREATE TABLE > CREATE TABLE authors (id serial PRIMARY KEY, first_name varchar(20), last_name varchar(20)); CREATE TABLE > \dt # список таблиц (команда psql) Схема | Имя | Тип | Владелец --------+----------+---------+---------- public | articles | таблица | blog public | authors | таблица | blog (2 строки) > \q
Удалить таблицу базы данных можно с помощью оператора DROP TABLE
DROP TABLE test;
Привилегии (права)
В PostgreSQL для работы с объектами кластера роль должна иметь привилегии к этим объектам — таблицам, функциям, представлениям. Только владелец объекта базы данных может использовать или изменять его, если конкретный доступ к нему не был предоставлен другим ролям. Это поведение может быть изменено, чтобы на новые объекты, которые создает роль, автоматически предоставлялись конкретные привилегии другим ролям, но не из коробки.
1. Привилегии объектов
Привилегии для базы данных
CONNECT— разрешает подключение к базе данныхCREATE— разрешает создавать схемы внутри базы данныхTEMPORARY— разрешает создавать временные таблицы
Привилегии для таблицы
SELECT— право на чтение данныхINSERT— право на вставку данныхUPDATE— право на изменение строкREFERENCES— право ссылаться на таблицуDELETE— право на удаление строкTRUNCATE— право на очистка таблицыTRIGGER— право на создание триггеров
Привилегии для представления
SELECT— право на чтение данныхTRIGGER— право на создание триггеров
Привилегии для последовательности
SELECT— право на чтениеUPDATE— право на изменение
Привилегии для схемы
CREATE— право создавать объекты внутри схемыUSAGE— право использовать объекты в схеме
С точки зрения управления доступом роли можно разбить на несколько групп
- Суперпользователь — полный доступ ко всем объектам, проверки не выполняются.
- Владелец — тот, кто создал объект. Владелец имеет все права на принадлежащий ему объект.
- Остальные роли — доступ только в рамках выданных прав на определённый объект. Права могут выдать владельцы на свои объекты. Или суперпользователь — на любой другой объект.
2. Операторы GRANT и REVOKE
Выдать привилегию можно с помощью оператора GRANT
GRANT привилегии ON объект TO роль
Забрать привилегию можно с помощью оператора REVOKE
REVOKE привилегии ON объект FROM роль
Выданной привилегией можно пользоваться, но нельзя передавать другим ролям. Но владелец или суперпользователь может вместе с привилегией выдать дополнительную опцию, которая разрешит передавать привилегию другим ролям. Выдача привилегии с правом её передачи выполняется с помощью WITH GRAND OPTION.
GRANT привилегии ON объект TO роль WITH GRAND OPTION
Допустим, мы дали привилегию вместе с правом её передачи. Затем роль воспользовалась своим правом и передала привилегию другим ролям. Тогда забрать эту привилегию можно только каскадно у этой роли и у других ролей с помощью CASCADE.
REVOKE привилегии ON объект FROM роль CASCADE
Можно не отбирать привилегию, а только отобрать право её передачи
REVOKE GRANT OPTION FOR привилегии ON объект FROM роль
public не видна, но про неё следует помнить. Это групповая роль, в которую включены все остальные роли. Это означает, что все роли по умолчанию будут иметь привилегии, наследуемые от public. Поэтому иногда у public отбирают некоторые привилегии, чтобы отнять их у всех пользователей.
3. Привилегии по умолчанию
Привилегии по умолчанию — это такие привилегии, которые добавятся к каким-то ролям на объект при его создании. Например роль blog хочет чтобы при создании новой таблицы доступ к ней сразу же получала роль shop. Привилегии по умолчанию создаются оператором ALTER DEFAULT PRIVILEGES.
ALTER DEFAULT PRIVILEGES [FOR ROLE роль_создатель] [IN SCHEMA схема] GRANT привилегии ON класс_объектов TO роль_получательВ примере выше
класс_объектов — может быть таблица, функция, представление и т.п. То есть, когда роль_создатель добавляет какой-то объект этого класса — срабатывает оператор GRANT для роль_получатель. Если FOR ROLE пропущено — оператор ALTER будет воздействовать на объекты, созданные текущим пользователем. Если IN SCHEMA пропущено — оператор ALTER будет воздействовать на объекты, созданные в любой схеме.
ALTER DEFAULT PRIVILEGES предназначен для изменения привилегий по умолчанию для объектов, которые будут созданы в будущем. Этот оператор не влияет на объекты, которые уже существуют. Для изменения привилегий уже существующих объектов предназначены операторы GRANT и REVOKE .
Аналогично можно удалять такие привилегии
ALTER DEFAULT PRIVILEGES [FOR ROLE роль_создатель] [IN SCHEMA схема] REVOKE привилегии ON класс_объектов FROM роль_получатель
Например сделаем так, чтобы при создании функций (любым пользователем в любой схеме), право их выполнять забиралось у роли public. Затем придется отдельным ролям предоставлять эту привилегию вручную.
ALTER DEFAULT PRIVILEGES REVOKE EXECUTE ON FUNCTIONS FROM public;
4. Права для таблицы
Чаще всего работа с базой данных — это работа с таблицами. Так что если возникли трудности с выборкой данных или записью в таблицу — нужно в первую очередь посмотреть права. В базе данных blog мы создали таблицы articles и authors — давайте посмотрим права на них.
$ psql --dbname=blog --username=blog --host=localhost psql (16.3 (Ubuntu 16.3-1.pgdg24.04+1)) Введите "help", чтобы получить справку. > \dp Схема | Имя | Тип | Права доступа | Права для столбцов | Политики --------+----------+---------+---------------+--------------------+---------- public | articles | таблица | | | public | authors | таблица | | | (2 строки) > GRANT SELECT ON articles TO shop; GRANT > \dp Схема | Имя | Тип | Права доступа | Права для столбцов | Политики --------+----------+---------+-------------------+--------------------+---------- public | articles | таблица | blog=arwdDxt/blog+| | | | | shop=r/blog | | public | authors | таблица | | | (2 строки) > \q
Если столбец «Права доступа» для таблицы пуст, это значит, что действуют стандартные права. Права по умолчанию всегда включают все права для владельца и могут также включать некоторые права для public. Первый оператор GRANT или REVOKE приводит к созданию записи прав по умолчанию, а затем изменяет эту запись в соответствии с заданным запросом.
Запись blog=arwdDxt/blog+shop=r/blog изначает, что у пользователя blog есть стандартные права arwdDxt, которые были выданы ему пользователем blog. Кроме того, были выданы права на чтение r (read) пользователю shop пользователем blog.
Право SELECT обозначается как r (от read), право INSERT — как a (от append), право UPDATE — как w (от write), право DELETE — как d (от delete) — и так далее. Звездочка * после права означает, что есть возможность передачи этого права другому пользователю (роли).
Схема (schema)
Кластер баз данных PostgreSQL содержит одну или несколько именованных экземпляров баз. На уровне кластера создаются роли и некоторые другие объекты. При этом в рамках одного подключения к серверу можно обращаться к данным только одной базы — той, что была выбрана при установлении соединения.
Каждый экземпляр базы также содержит одну или несколько именованных схем, которые в свою очередь содержат таблицы. Схемы также содержат именованные объекты других видов, включая типы данных, функции и операторы. Одно и то же имя объекта можно свободно использовать в разных схемах, например схемы schema_one и schema_two могут содержать таблицы с именем my_table.
Создание новой схемы
CREATE SCHEMA myschema;
Удаление пустой схемы
DROP SCHEMA myschema;
Удаление схемы со всеми содержащимися в ней объектами
DROP SCHEMA myschema CASCADE;
По умолчанию пользователь не может обращаться к объектам в чужих схемах. Чтобы изменить это, владелец схемы должен предоставить пользователю право USAGE. По умолчанию все пользователи имеют это право для схемы public. Чтобы пользователь мог создавать объекты внутри схемы — владелец схемы должен предоставить пользователю право CREATE.
Права пользователя test на схему public (f означает false, t означает true) для текущей базы
SELECT pg_catalog.has_schema_privilege('test', 'public', 'CREATE') AS "create", pg_catalog.has_schema_privilege('test', 'public', 'USAGE') AS "usage";
create | usage --------+------- f | t
Тут важно понимать, что таблицы создаются не внутри базы данных, а внутри схемы, даже если не указывать это явно — в этом случае подразумевается схема public. Схема public существует внутри любой базы данных, ее владельцем является пользователь postgres.
Создадим пользователя testing и базу testing, предоставим пользователю все права на базу и все права на использование схемы public. Но здесь допущена ошибка — права на схему выдаются внутри базы postgres — совсем не то, что нужно.
$ whoami postgres $ psql
CREATE DATABASE testing; CREATE ROLE testing WITH LOGIN PASSWORD 'testing'; GRANT ALL ON DATABASE testing TO testing; GRANT ALL ON SCHEMA public TO testing;
Проверяем права доступа пользователя testing на схему public (но это права на схему внутри базы postgres)
SELECT pg_catalog.has_schema_privilege('testing', 'public', 'CREATE') AS "create", pg_catalog.has_schema_privilege('testing', 'public', 'USAGE') AS "usage";
create | usage --------+------- t | t
Подключаемся под пользователем testing к базе данных testing и проверяем права на использование схемы public
$ whoami postgres $ psql --username=testing --dbname=testing --host=localhost
SELECT pg_catalog.has_schema_privilege('testing', 'public', 'CREATE') AS "create", pg_catalog.has_schema_privilege('testing', 'public', 'USAGE') AS "usage";
create | usage --------+------- f | t
У пользователя testing в базе данных testing нет права CREATE для схемы public — так что при создании таблицы получим ошибку «нет доступа к схеме public». Нужно подключиться к базе testing под суперпользователем postgres и выдать права пользователю testing на схему public внутри базы testing.
$ whoami postgres $ psql --dbname=testing
GRANT ALL ON SCHEMA public TO testing;
Выданное по ошибке пользователю testing право CREATE для схемы public внутри базы данных postgres — нужно отозвать.
$ whoami postgres $ psql
REVOKE CREATE ON SCHEMA public FROM testing;
Файлы конфигурации
1. Файл конфигурации pg_hba.conf
Управляет аутентификацией клиентов. Каждая запись обозначает тип соединения, диапазон ip-адресов клиента, имя базы данных, имя пользователя и способ аутентификации. Используется первая подходящая запись с соответствующим типом, адресом, указанной базой и именем. Если была выбрана подходящая запись и аутентификация не прошла — следующие записи не рассматриваются. Если ни одна из записей не подошла — в доступе будет отказано.
Каждая запись может быть директивой включения или записью аутентификации. Директивы включения указывают, что нужно обработать дополнительные файлы с записями. Директивы включения содержат только два поля — include, include_if_exists или include_dir и включаемый файл или каталог. Путь к файлу или каталогу может задаваться и как абсолютный, и как относительный. Для include_dir будут включены все файлы, которые не начинающиеся с точки и заканчиваются на .conf.
Записи могут иметь следующие форматы
local база пользователь метод-аутентификации [параметры-аутентификации] host база пользователь адрес метод-аутентификации [параметры-аутентификации] hostssl база пользователь адрес метод-аутентификации [параметры-аутентификации] hostnossl база пользователь адрес метод-аутентификации [параметры-аутентификации] host база пользователь ip-адрес ip-маска метод-аутентификации [параметры-аутентификации] hostssl база пользователь ip-адрес ip-маска метод-аутентификации [параметры-аутентификации] hostnossl база пользователь ip-адрес ip-маска метод-аутентификации [параметры-аутентификации] include файл include_if_exists файл include_dir каталог
Значения полей описаны ниже
local— подключение через unix-сокет; без этой записи подключения через unix-сокет невозможны.host— подключение по tcp/ip; разрешаются подключения как c SSL, так и без SSL.hostssl— подключение по tcp/ip с применением шифрования SSL.hostnossl— подключение по tcp/ip без применения шифрования SSL.база— каким именам баз данных соответствует эта запись. Значениеallопределяет, что подходят все базы данных. Значениеsameuserопределяет, что данная запись соответствует, если имя запрашиваемой базы совпадает с именем пользователя. Значениеsameroleопределяет, что пользователь должен быть членом роли с таким же именем, как у базы.пользователь— какому пользователю базы данных соответствует эта запись. Значениеallуказывает, что запись соответствует всем пользователям. Любое другое значение задаёт либо имя конкретного пользователя базы данных, либо имя группы (если начинается с+). В PostgreSQL нет никакой разницы между пользователем и группой; знак+означает «совпадение любых ролей, которые прямо или косвенно являются членами роли», тогда как имя без знака+является подходящим только для этой конкретной роли.адрес— адрес клиентской машины, которой соответствует данная запись. Может содержать имя компьютера, диапазон ip-адресов или ключевые слово. Диапазон адресов IPv4 может быть указан как172.20.143.89/32для одного компьютера,172.20.143.0/24— для небольшой сети,10.6.0.0/16— для крупной сети. Значениеallсоответствует любому ip-адресу, значениеsamehost— любому ip-адресу данного сервера, значениеsamenet— любому ip-адресу подсети, к которой сервер подключён напрямую.ip-адресиip-маска— могут быть использованы как альтернатива записиip-адрес/маска.метод-аутентификации— метод аутентификации, когда подключение соответствует этой записи.
listen_addresses — по умолчанию принимаются только подключения через localhost.
ssl.
Некоторые методы аутентификации
trust— разрешает безусловное подключение. Этот метод позволяет тому, кто может подключиться к кластеру, войти под любым пользователем без ввода пароля и без какой-либо другой аутентификации.reject— отклоняет подключение безусловно. Эта возможность полезна для «фильтрации», например, одна строка отклоняет попытку подключения одного компьютера, при этом следующая строка позволяет подключиться остальным.scram-sha-256— проверяет пароль пользователя, производя аутентификацию SCRAM-SHA-256.password— требует для аутентификации введения клиентом незашифрованного пароля. Поскольку пароль посылается простым текстом через сеть, такой способ не стоит использовать, если сеть не вызывает доверия.peer— для соединений через unix-сокет. Имя пользователя операционной системы должно соответствовать имени пользователя кластера — тогда аутентификация будет успешной.
Пример файла конфигурации
# TYPE DATABASE USER ADDRESS METHOD # Пользователь ОС postgres не имеет пароля, войти под ним можно только с использованием sudo. # Суперпользователь БД postgres может подключиться к кластеру без пароля через unix-сокет. local all postgres peer # Существующие пользователи ОС, у которых есть пользователь БД с таким же именем, подключаются # к кластеру с использованием unix-сокета без пароля. local all all peer # Пользователи БД, у которых нет пользователя ОС с таким же именем, подключаются к кластеру по # tcp/ip через интерфейс localhost с использованием пароля. host all all localhost scram-sha-256
2. Файл конфигурации postgresql.conf
Это главный файл конфигурации, от настроек которого зависит производительность. Значения по умолчанию установлены таким образом, чтобы обеспечить возможность запуска на слабом сервере с минимальной конфигурацией.
Опция shared_buffers
Оперативная память, которая используется для кэширования данных. Рекомендуемое значение — 25% от общего размера памяти на сервере. PostgreSQL использует два кэша при чтении-записи — свой внутренний и операционной системы. Поэтому выделять для shared_buffers более 40% ОЗУ вряд ли будет полезно. После изменения значения опции требуется перезапуск сервера. При увеличении shared_buffers обычно требуется соответственно увеличить max_wal_size.
Установка значения в 25% ОЗУ — это только начальная точка. Дальше нужно отслеживать коэффициент попадания данных в кэш. В идеале коэффициент попадания должен быть близок к 100%. Если коэффициент попадания ниже 80% — следует увеличить значение shared_buffers. Однако, если увеличение значения опции означает более 40% общей доступной памяти — пора задуматься о новом сервере.
Запрос для получения коэффициента попадания в кэш
SELECT sum(heap_blks_read) AS heap_read, sum(heap_blks_hit) AS heap_hit, sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) AS ratio FROM pg_statio_user_tables;
Опция work_mem
Оперативная память, которая используется для сортировок, построения хеш-таблиц. Если это значение слишком маленькое — данные в процессе выполнения SQL-запроса будут сбрасываться на диск. В рамках одного SQL-запроса данная опция может быть использована несколько раз. Если SQL-запрос содержит две операции сортировки, то память, которая может использоваться для его выполнения — как минимум work_mem * 2. Кроме того, SQL-запросы с сортировкой могут выполняться одновременно в нескольких сеансах.
Хеш-таблицы используются при соединениях и агрегировании по хешу, мемоизации узлов, а также обработке подзапросов IN. Операции вычисления хеша обычно более требовательны к памяти, чем операции сортировки. Поэтому ограничение памяти для хеш-таблиц определяется произведением work_mem * hash_mem_multiplier и может превышать установленное значение work_mem.
Можно изменить work_mem на уровне кластера (это будет влиять на все запросы), для отдельной роли, на уровне сеанса или даже для одного SQL-запроса. При увеличении значения опции на уровне сервера — можно легко исчерпать доступную память, если несколько сеансов одновременно выполняют сложные SQL-запросы с сортировками.
Для начала можно выставить значение от 32 до 64 Мбайт. И далее мониторить файл лога — будут данные сбрасываться на диск или нет.
-- изменение значения опции для пользователя (роли) ALTER ROLE testing SET work_mem = '64MB';
-- изменение значения опции для сеанса до момента RESET или до окончания сеанса SET SESSION work_mem = '64MB'; -- команда сбрасывает значение work_mem, установленное где-то выше командой SET RESET work_mem;
-- изменение значения опции для одного запроса SET LOCAL work_mem = '64MB'; SELECT * FROM users ORDER BY lower(last_name);
Опция effective_cache_size
Значение опции служит подсказкой для планировщика, сколько оперативной памяти у него в запасе. За счёт данной опции планировщик может чаще использовать индексы, строить hash таблицы. Наиболее часто используемое значение — 75% от общей памяти на сервере.
Опция maintenance_work_mem
Определяет максимальное количество оперативной памяти для служебных операций типа VACUUM, CREATE INDEX, CREATE FOREIGN KEY. Наиболее часто используемое значение — work_mem * 4.
Опция random_page_cost
Связана с опцией seq_page_cost (которая всегда должна быть равна 1) и задает соотношение скоростей произвольного и последовательного доступа. По умолчанию предполагается, что произвольный доступ в 4 раза медленнее последовательного (что справедливо для обычных HDD-дисков). Однако для дисковых массивов и SSD-дисков значение random_page_cost надо уменьшить.
random_page_cost = 1.2
Опция autovacuum
Очень ответственной является настройка автоочистки autovacuum. Этот процесс занимается «сборкой мусора» и выполняет ряд других важных для системы задач. Опция autovacuum по умолчанию включена, но следует установить значение еще одной опции.
# чтобы автоматическая очистка выполнялась чаще и меньшими порциями autovacuum_vacuum_scale_factor = 0.01
Очистка не блокирует другие процессы, но тем не менее создает нагрузку на систему и может оказывать заметное влияние на производительность. Чтобы иметь возможность управлять интенсивностью очистки и, следовательно, ее влиянием на систему, процесс чередует работу и ожидание. Очистка выполняет примерно vacuum_cost_limit условных единиц работы, а затем засыпает на vacuum_cost_delay мс.
Настройки по умолчанию устанавливают vacuum_cost_limit=200, vacuum_cost_delay=0. Последний ноль фактически означает, что очистка при работе не засыпает. Это сделано из соображения, что если уж администратору пришлось запускать VACUUM вручную, то он, вероятно, хочет выполнить очистку как можно быстрее.
Регулирование нагрузки при автоматической очистке работает так же, как и для обычной. Но чтобы очистка, запускаемая вручную, и автоочистка могли работать с разной интенсивностью, были добавлены опции autovacuum_vacuum_cost_limit и autovacuum_vacuum_cost_delay. Если эти опции принимают значение -1, то используется значения из vacuum_cost_limit и vacuum_cost_delay.
Опция effective_io_concurrency
Задаёт допустимое число параллельных операций ввода/вывода, которое сообщает PostgreSQL о том, сколько операций ввода/вывода могут быть выполнены одновременно. Чем больше это число, тем больше операций ввода/вывода будет пытаться выполнить параллельно PostgreSQL в отдельном сеансе. Для SSD рекомендуется значение около 200, для HDD более подходящими будет значение 2, потому что HDD хуже справляется с параллельными операциями из-за механических ограничений.
Конфигурация кластера
1. Текущие настройки кластера
Текущие значения настроек кластера можно посмотреть с помощью команды SHOW. Эти настройки можно установить, воспользовавшись оператором SET или задать их в файле конфигурации postgresql.conf. Кроме того, получить значения настроек можно из представления pg_settings.
SHOW log_duration; -- текущее значение по умолчанию — off off SET log_duration = 'on'; -- установка значения во время сессии SHOW log_duration; -- текущее значение для этой сессии — on on RESET log_duration; -- сброс настройки обратно в значение off
Примеры просмотра настроек кластера, используя представление pg_settings
SELECT name, setting, context, source FROM pg_settings WHERE name ~ '^log_';
name | setting | context | source -----------------------------------+--------------------------------+-------------------+-------------------- log_autovacuum_min_duration | 600000 | sighup | default log_checkpoints | on | sighup | default log_connections | off | superuser-backend | default log_destination | stderr | sighup | default log_directory | log | sighup | default log_disconnections | off | superuser-backend | default log_duration | off | superuser | default log_error_verbosity | default | superuser | default log_executor_stats | off | superuser | default log_file_mode | 0600 | sighup | default log_filename | postgresql-%Y-%m-%d_%H%M%S.log | sighup | default log_hostname | off | sighup | default log_line_prefix | %m [%p] %q%u@%d | sighup | configuration file log_lock_waits | off | superuser | default log_min_duration_sample | -1 | superuser | default log_min_duration_statement | -1 | superuser | default log_min_error_statement | error | superuser | default log_min_messages | warning | superuser | default log_parameter_max_length | -1 | superuser | default log_parameter_max_length_on_error | 0 | user | default log_parser_stats | off | superuser | default log_planner_stats | off | superuser | default log_recovery_conflict_waits | off | sighup | default log_replication_commands | off | superuser | default log_rotation_age | 1440 | sighup | default log_rotation_size | 10240 | sighup | default log_startup_progress_interval | 10000 | sighup | default log_statement | none | superuser | default log_statement_sample_rate | 1 | superuser | default log_statement_stats | off | superuser | default log_temp_files | -1 | superuser | default log_timezone | Etc/UTC | sighup | configuration file log_transaction_sample_rate | 0 | superuser | default
SELECT name, short_desc FROM pg_settings WHERE name ~ '^log_';
name | short_desc -----------------------------------+------------------------------------------------------------------------------- log_autovacuum_min_duration | Задаёт предельное время выполнения автоочистки, при превышении которого эта... log_checkpoints | Протоколировать каждую контрольную точку. log_connections | Протоколировать устанавливаемые соединения. log_destination | Определяет, куда будет выводиться протокол сервера. log_directory | Задаёт целевой каталог для файлов протоколов. log_disconnections | Протоколировать конец сеанса, отмечая длительность. log_duration | Протоколировать длительность каждого выполненного SQL-оператора. log_error_verbosity | Задаёт детализацию протоколируемых сообщений. log_executor_stats | Запись статистики выполнения запросов в протокол сервера. log_file_mode | Задаёт права доступа к файлам протоколов. log_filename | Задаёт шаблон имени для файлов протоколов. log_hostname | Записывать имя узла в протоколы подключений. log_line_prefix | Определяет содержимое префикса каждой строки протокола. log_lock_waits | Протоколировать длительные ожидания в блокировках. log_min_duration_sample | Задаёт предельное время выполнения оператора из выборки, при превышении кот... log_min_duration_statement | Задаёт предельное время выполнения любого оператора, при превышении которог... log_min_error_statement | Включает протоколирование для SQL-операторов, выполненных с ошибкой этого и... log_min_messages | Ограничивает уровни протоколируемых сообщений. log_parameter_max_length | Задаёт максимальный размер данных (в байтах), выводимых в значениях привяза... log_parameter_max_length_on_error | Задаёт максимальный размер данных (в байтах), выводимых в значениях привяза... log_parser_stats | Запись статистики разбора запросов в протокол сервера. log_planner_stats | Запись статистики планирования в протокол сервера. log_recovery_conflict_waits | Протоколировать события ожидания разрешения конфликтов при восстановлении н... log_replication_commands | Протоколировать каждую команду репликации. log_rotation_age | Задаёт время задержки перед принудительным переключением на следующий файл ... log_rotation_size | Задаёт максимальный размер, которого может достичь файл журнала до переключ... log_startup_progress_interval | Интервал между обновлениями состояния длительных операций, выполняемых при ... log_statement | Задаёт тип протоколируемых операторов. log_statement_sample_rate | Доля записываемых в журнал операторов с длительностью, превышающей log_min_... log_statement_stats | Запись общей статистики производительности в протокол сервера. log_temp_files | Фиксирует в протоколе превышение временными файлами заданного размера (в КБ). log_timezone | Задаёт часовой пояс для вывода времени в сообщениях протокола. log_transaction_sample_rate | Задаёт долю транзакций, все операторы которых будут записываться в журнал с... log_truncate_on_rotation | Очищать уже существующий файл с тем же именем при прокручивании протокола.
2. Настройка ротации логов
После установки кластера уже существует файл конфигурации для ротации логов в директории /var/log/postgresql — дополнительная настройка не нужна.
/var/log/postgresql/*.log {
weekly
rotate 10
copytruncate
delaycompress
compress
notifempty
missingok
su root root
}
3. Лог медленных запросов
За это отвечает опция log_min_duration_statement. Значение -1 отключает логирование меделенных запросов, значение 0 предписывает записывать в лог все запросы, положительное число задает количество миллисекунд времени выполнения, при достижении которого запрос попадает в лог.
$ sudo nano /etc/postgresql/16/main/postgresql.conf
# логировать запросы продолжительностью более 100 мс log_min_duration_statement = 100
$ sudo systemctl restart postgresql.service
$ cat /var/log/posgresql/postgresql-16-main.log 2024-07-17 12:05:43.985 UTC [10068] СООБЩЕНИЕ: для приёма подключений по адресу IPv4 "127.0.0.1" открыт порт 5432 2024-07-17 12:05:43.989 UTC [10068] СООБЩЕНИЕ: для приёма подключений открыт Unix-сокет "/var/run/postgresql/..." 2024-07-17 12:05:44.000 UTC [10071] СООБЩЕНИЕ: система БД была выключена: 2024-07-17 12:05:43 UTC 2024-07-17 12:05:44.011 UTC [10068] СООБЩЕНИЕ: система БД готова принимать подключения 2024-07-17 12:06:43.577 UTC [10102] shop@shop СООБЩЕНИЕ: продолжительность: 9686.574 мс, оператор: SELECT creat...
4. Оптимизация значения work_mem
Чтобы отследить слишком маленькое значение work_mem — нужно посмотреть вывод плана EXPLAIN ANALYZE для больших сложных запросов. Всякий раз, когда план содержит «Sort Method: external merge Disk: xxxxkB» — запрос сбрасывал данные на диск.
Давайте создадим таблицу, добавим в нее данные, а потом выполним сложный запрос с сортировкой.
CREATE TABLE orders ( id serial PRIMARY KEY, created timestamp NOT NULL, amount decimal(10, 2) NOT NULL );
INSERT INTO orders (created, amount) SELECT generate_series( '2022-01-01'::timestamp, '2023-12-31'::timestamp, '1 minute'::interval ) AS created, (random() * 1000 + 500)::decimal(10,2) AS amount FROM generate_series(1, 10);
Это таблица заказов в интернет-магазине, даты создаются за период с начала 2022 года по конец 2023 года с интервалом в одну минуту. Для каждой сгенерированной даты создаются 10 строк со случайной суммой заказа от 500 до 1500, округленной до двух знаков после запятой.
SELECT * FROM orders ORDER BY created LIMIT 30;
id | created | amount ---------+---------------------+--------- 6298567 | 2022-01-01 00:00:00 | 504.30 8398089 | 2022-01-01 00:00:00 | 1389.78 3149284 | 2022-01-01 00:00:00 | 842.87 .......... еще 7 строк .......... 7348329 | 2022-01-01 00:01:00 | 1377.49 4199046 | 2022-01-01 00:01:00 | 1117.25 2099524 | 2022-01-01 00:01:00 | 1135.97 .......... еще 7 строк .......... 5248808 | 2022-01-01 00:02:00 | 1025.79 1049764 | 2022-01-01 00:02:00 | 825.52 2099525 | 2022-01-01 00:02:00 | 541.96 .......... еще 7 строк ..........
Теперь предположим, что мы хотим получить общие суммы продаж, отсортированные по дате
EXPLAIN ANALYZE SELECT created, sum(amount) FROM orders GROUP BY created ORDER BY created;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=128469.67..128521.84 rows=200 width=40) (actual time=33388.838..40097.141 ro...)
Group Key: created
-> Gather Merge (cost=128469.67..128516.34 rows=400 width=40) (actual time=33388.793..36004.628 rows=30...)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=127469.64..127470.14 rows=200 width=40) (actual time=33163.798..33488.561 rows=1029...)
Sort Key: created
Sort Method: external merge Disk: 83424kB
Worker 0: Sort Method: external merge Disk: 83728kB
Worker 1: Sort Method: external merge Disk: 83704kB
-> Partial HashAggregate (cost=127459.50..127462.00 rows=200 width=40) (actual time=12617.7...)
Group Key: created
Batches: 133 Memory Usage: 8257kB Disk Usage: 132856kB
Worker 0: Batches: 101 Memory Usage: 8361kB Disk Usage: 130176kB
Worker 1: Batches: 117 Memory Usage: 8361kB Disk Usage: 129720kB
-> Parallel Seq Scan on orders (cost=0.00..107261.00 rows=4039700 width=24) (actual t...)
Planning Time: 5.941 ms
JIT:
Functions: 36
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 15.585 ms, Inlining 0.000 ms, Optimization 10.032 ms, Emission 181.048 ms, Total 206.66...
Execution Ti
Давайте увеличим для текущей сессии значение work_mem до 200 Мбайт и еще раз посмотрим результаты
SET work_mem = '200MB'; EXPLAIN ANALYZE SELECT created, sum(amount) FROM orders GROUP BY created ORDER BY created;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Sort (cost=339909.01..342480.62 rows=1028646 width=40) (actual time=10118.215..10289.054 rows=1049761 loops=1)
Sort Key: created
Sort Method: quicksort Memory: 94220kB
-> HashAggregate (cost=224328.72..237186.79 rows=1028646 width=40) (actual time=8305.632..9649.494 rows...)
Group Key: created
Batches: 5 Memory Usage: 409649kB Disk Usage: 31976kB
-> Seq Scan on orders (cost=0.00..171840.48 rows=10497648 width=14) (actual time=0.055..1902.364 ...)
Planning Time: 0.075 ms
JIT:
Functions: 11
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 0.962 ms, Inlining 0.000 ms, Optimization 1.878 ms, Emission 16.958 ms, Total 19.798 ms
Execution Time: 10399.661 ms
(13 строк)
Теперь при сортировке временные файлы не используются, все происходит в оперативной памяти. Еще видим, что использование диска при группировке тоже уменьшилось. Если мы увеличим значение hash_mem_multiplier — то группировка вовсе не будет использовать диск.
SET hash_mem_multiplier = 3; EXPLAIN ANALYZE SELECT created, sum(amount) FROM orders GROUP BY created ORDER BY created;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Sort (cost=339909.01..342480.62 rows=1028646 width=40) (actual time=9404.753..9576.415 rows=1049761 loops=1)
Sort Key: created
Sort Method: quicksort Memory: 94220kB
-> HashAggregate (cost=224328.72..237186.79 rows=1028646 width=40) (actual time=8176.137..8919.722 ro...)
Group Key: created
Batches: 1 Memory Usage: 442385kB
-> Seq Scan on orders (cost=0.00..171840.48 rows=10497648 width=14) (actual time=0.117..1699.53...)
Planning Time: 0.061 ms
JIT:
Functions: 7
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 0.794 ms, Inlining 0.000 ms, Optimization 0.345 ms, Emission 10.108 ms, Total 11.247 ms
Execution Time: 9686.574 ms
(13 строк)
Главная трудность — как обнаруживать SQL-запросы, которые сбрасывают данные на диск. Для этого можно записывать в лог медленные запросы вместе с EXPLAIN ANALYZE.
$ sudo nano /etc/postgresql/16/main/postgresql.conf
# отключить логирование медленных запросов средствами сервера log_min_duration_statement = -1 # загрузить модуль auto_explain при запуске сервера базы данных shared_preload_libraries = 'auto_explain' # включить логирование медленных запросов с помощью этого модуля auto_explain.log_min_duration = 100 # записывать в лог результат EXPLAIN ANALYZE, не просто EXPLAIN auto_explain.log_analyze = 1
$ sudo systemctl restart postgresql.service
Теперь в логах можно увидеть полную информацию по медленным запросам и оптимизировать значение work_mem.
$ cat /var/log/posgresql/postgresql-16-main.log 2024-07-17 12:46:37.969 UTC [11048] shop@shop СООБЩЕНИЕ: duration: 20344.505 ms plan: Query Text: SELECT created, sum(amount) FROM orders GROUP BY created ORDER BY created LIMIT 10; Limit (cost=550110.20..550112.81 rows=10 width=40) (actual time=20261.263..20344.483 rows=10 loops=1) -> Finalize GroupAggregate (cost=550110.20..818432.13 rows=1028646 width=40) (actual time=1990...) Group Key: created -> Gather Merge (cost=550110.20..790144.36 rows=2057292 width=40) (actual time=19906.839...) Workers Planned: 2 Workers Launched: 2 -> Sort (cost=549110.18..551681.80 rows=1028646 width=40) (actual time=19742.444.....) Sort Key: created Sort Method: external merge Disk: 82448kB Worker 0: Sort Method: external merge Disk: 81576kB Worker 1: Sort Method: external merge Disk: 79832kB -> Partial HashAggregate (cost=390814.86..446387.97 rows=1028646 width=40) (...) Group Key: created Planned Partitions: 4 Batches: 5 Memory Usage: 204849kB Disk Usage: 52... Worker 0: Batches: 5 Memory Usage: 204849kB Disk Usage: 52264kB Worker 1: Batches: 5 Memory Usage: 204849kB Disk Usage: 48768kB -> Parallel Seq Scan on orders (cost=0.00..110604.20 rows=4374020 width... JIT: Functions: 37 Options: Inlining true, Optimization true, Expressions true, Deforming true Timing: Generation 15.671 ms, Inlining 1071.485 ms, Optimization 993.944 ms, Emission 670.524 ms,...
Есть еще один способ оптимизации значения work_mem. Можно влючить запись в лог-файл информации о временных файлах, которые создаются, когда в процессе выполнения SQL-запроса данные сбрасываются на диск. По размеру этих файлов можно понять, сколько памяти нужно выделить дополнительно, чтобы данные не сбрасывались на диск.
# Значение ноль записывает в лог информацию о всех временных файлах. Положительное значение предписывает записывать в # лог информацию о temp-файлах, размер которых в килобайтах превышает это значение. Значение -1 отключает логирование. log_temp_files = 0
2024-07-19 10:13:28.428 UTC [1427] СООБЩЕНИЕ: временный файл: путь "base/pgsql_tmp/pgsql_tmp1427.1", размер 85204992 2024-07-19 10:13:28.428 UTC [1427] ОПЕРАТОР: SELECT created, sum(amount) FROM orders GROUP BY created ORDER BY cr... 2024-07-19 10:13:28.431 UTC [1428] СООБЩЕНИЕ: временный файл: путь "base/pgsql_tmp/pgsql_tmp1428.1", размер 84115456 2024-07-19 10:13:28.431 UTC [1428] ОПЕРАТОР: SELECT created, sum(amount) FROM orders GROUP BY created ORDER BY cr... 2024-07-19 10:13:28.460 UTC [1427] СООБЩЕНИЕ: временный файл: путь "base/pgsql_tmp/pgsql_tmp1427.0", размер 54165504 2024-07-19 10:13:28.460 UTC [1427] ОПЕРАТОР: SELECT created, sum(amount) FROM orders GROUP BY created ORDER BY cr... 2024-07-19 10:13:28.461 UTC [1428] СООБЩЕНИЕ: временный файл: путь "base/pgsql_tmp/pgsql_tmp1428.0", размер 53633024 2024-07-19 10:13:28.461 UTC [1428] ОПЕРАТОР: SELECT created, sum(amount) FROM orders GROUP BY created ORDER BY cr... 2024-07-19 10:13:28.506 UTC [1423] shop@shop СООБЩЕНИЕ: временный файл: путь "base/pgsql_tmp/pgsql_tmp1423.1", ра... 2024-07-19 10:13:28.506 UTC [1423] shop@shop ОПЕРАТОР: SELECT created, sum(amount) FROM orders GROUP BY created O... 2024-07-19 10:13:28.523 UTC [1423] shop@shop СООБЩЕНИЕ: временный файл: путь "base/pgsql_tmp/pgsql_tmp1423.0", ра... 2024-07-19 10:13:28.523 UTC [1423] shop@shop ОПЕРАТОР: SELECT created, sum(amount) FROM orders GROUP BY created O...
Дальше действуем со старой схеме — мониторим лог-файл и постепенно увеличиваем значение work_mem, пока сообщения о создании временных файлов не пропадут вовсе или их будет пренебрежительно мало.
pgbadger — это анализатор журналов PostgreSQL, который быстро строит подробные отчёты, обрабатывая файлы журналов сервера. Можно передать для анализа отдельный файл, список файлов или команду, выдающую список файлов. Если передать дефис, содержимое журнала будет считываться из стандартного ввода. Документацию можно найти здесь.
Страницы, кэш и WAL
1. Что такое страницы
Любой файл, используемый для хранения объектов базы данных, делится на блоки одинаковой длины, которые часто называют страницами. По умолчанию PostgreSQL использует блоки по 8192 байта каждый. Блок — это единица, которая передается между жестким диском и оперативной памятью, а количество операций чтения-записи, необходимое для выполнения любого доступа к данным, равно количеству блоков, которые читаются или записываются.
Объекты базы данных состоят из логических элементов (строк таблиц, индексных записе и т.д.). PostgreSQL выделяет место для этих элементов блоками (страницами). Несколько мелких элементов могут находиться в одном блоке; более крупные элементы могут быть распределены между несколькими блоками.
Страницы сначала помещаются в буферный кеш — где их могут читать и изменять процессы. Если процессу понадобились какие-то данные — он их вначале ищет в буферном кэше. Если данных в кэше не оказалось — происходит обращение к операционной системе, чтобы прочитать эту страницу и поместить в буферный кэш. Операционная система имеет свой дисковый кэш и ищет эту страничку там — если не находит, то читает с диска и помещает в дисковый кэш. Затем из дискового кэша страничка помещается в буферный кэш для PostgreSQL.
Чтобы буферный кэш не переполнился — нужно редко используемые страницы из него вытеснять. Другими словами удалять из буфера. Если процессы изменили страницу, то она считается грязной, и перед вытеснением из буфера её нужно записать на диск. Если страницу не меняли то и записывать на диск её ещё раз не имеет смысла.
2. Журнал предзаписи (WAL)
То, что данные находятся в оперативной памяти — это хорошо. Но при сбое эти данные теряются, если не успели записаться на диск. После сбоя база данных становится рассогласованной. Какие-то измененные (грязные) страницы были записаны, другие не успели записаться. Журнал предварительной записи (WAL) — механизм, которым позволяет восстановить согласованность данных после сбоя.
Перед тем, как изменить какую-то страницу в памяти, нужно записать в журнал WAL — что именно будет изменяться. И запись в журнале должна попасть на диск раньше, чем сама страница будет записана на диск. В случае сбоя можно прочитать журнал предзаписи и выполнить все действия заново, чтобы восстановить согласованность данных.
Результатом использования WAL является значительное уменьшение количества запросов записи на диск, потому что для гарантии, что транзакция подтверждена, в записи на диск нуждается только файл WAL, а не каждый файл данных, изменённый в результате транзакции. Файл WAL записывается последовательно и таким образом затраты на синхронизацию WAL намного меньше, чем затраты на запись страниц с данными.
3. Контрольные точки
Остается еще вопрос — с какого момента начинать выполнение действий из журнала WAL при восстановлении. Начать с начала не получится — невозможно хранить все журнальные записи от старта сервера. Это потенциально и огромный объем, и такое же огромное время восстановления. Нужна такая постепенно продвигающаяся вперед точка, с которой можно начинать восстановление. И, соответственно, можно безопасно удалять все предшествующие журнальные записи.
Как получить контрольную точку? Самый простой вариант — периодически приостанавливать работу системы и сбрасывать все грязные страницы буферного и других кешей на диск. При этом, страницы только записываются, но не вытесняются из кэша. Такие точки будут удовлетворять условию, но, конечно, никто не захочет работать с системой, постоянно замирающей на неопределенное, но весьма существенное время.
Поэтому на практике все несколько сложнее — контрольная точка из точки превращается в отрезок. Есть момент начала создания контрольной точки и есть момент завершения создания контрольной точки. В этот промежуток времени, не прерывая работу и по возможности не создавая пиковых нагрузок, грязные страницы потихоньку сбрасываются на диск.
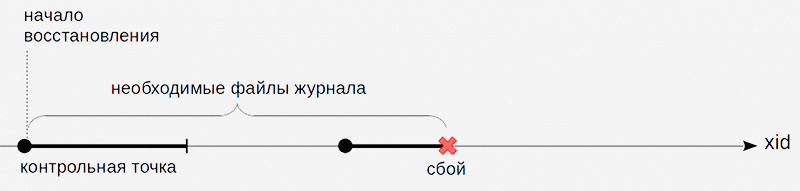
Когда все страницы, которые были грязными на момент начала создания контрольной точки, окажутся записанными, создание контрольной точки считается завершенным. Теперь (но не раньше) можно использовать момент начала в качестве той точки, с которой можно начинать восстановление. И журнальные записи вплоть до этого момента больше не нужны.
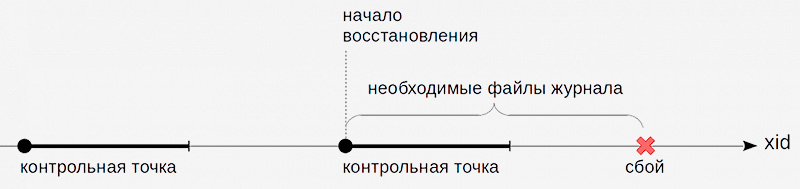
4. Опции настройки WAL
Контрольные точки автоматически создает отдельный серверный процесс. Точки создаются каждые checkpoint_timeout секунд либо при приближении к пределу max_wal_size, если это имеет место раньше. Значения по умолчанию — 5 минут и 1 Гбайт, соответственно.
Уменьшение значений checkpoint_timeout и/или max_wal_size приводит к более частому созданию контрольных точек. Это позволяет ускорить восстановление после краха, но увеличивает нагрузку из-за более частого сброса грязных страниц на диск.
Чтобы избежать повышенной нагрузки системы ввода/вывода, запись грязных страниц во время создания контрольной точки растягивается на определённый период времени. Этот период управляется опцией checkpoint_completion_target, которая по умолчанию имеет значение 0.9. Другими словами — запись грязных страниц занимает 90% времени между контрольными точками.
Опция max_wal_size задает максимальный размер журнала WAL. Когда размер превышает это значение — создается новая контрольная точка, даже если checkpoint_timeout предписывает создать ее позже. Для простой проверки можно использовать опцию checkpoint_warning. Если промежуток времени между контрольными точками будет меньше checkpoint_warning, то в лог-файл будет выдано сообщение с рекомендацией увеличить max_wal_size.
Давайте спровоцируем слишком частое создание контрольных точек из-за маленького значения max_wal_size.
checkpoint_timeout = 30s # предупреждение, если контрольные точки создаются по достижении max_wal_size, не по таймингу checkpoint_warning = 29s # задаем очень маленький размер журнала WAL, чтобы спровоцировать создание контрольных точек max_wal_size = 100MB min_wal_size = 50MB
$ cat /var/log/posgresql/postgresql-16-main.log 2024-07-21 09:54:31.903 UTC [1577] СООБЩЕНИЕ: начата контрольная точка: wal 2024-07-21 09:54:34.366 UTC [1577] СООБЩЕНИЕ: контрольная точка завершена: записано буферов: 2964 (18.1%); добавлено файлов WAL 0, удалено: 0, переработано: 3; запись=2.302 сек., синхр.=0.078 сек., всего=2.463 сек.; синхронизировано_файлов=3, самая_долгая_синхр.=0.050 сек., средняя=0.026 сек.; расстояние=47452 kB, ожидалось=50295 kB; lsn=4/53F26FE8, lsn redo=4/510EB278 2024-07-21 09:54:34.524 UTC [1577] СООБЩЕНИЕ: контрольные точки происходят слишком часто (через 3 сек.) 2024-07-21 09:54:34.524 UTC [1577] ПОДСКАЗКА: Возможно, стоит увеличить параметр "max_wal_size". 2024-07-21 09:54:34.526 UTC [1577] СООБЩЕНИЕ: начата контрольная точка: wal 2024-07-21 09:54:37.149 UTC [1577] СООБЩЕНИЕ: контрольная точка завершена: записано буферов: 3229 (19.7%); добавлено файлов WAL 0, удалено: 1, переработано: 2; запись=2.200 сек., синхр.=0.268 сек., всего=2.625 сек.; синхронизировано_файлов=4, самая_долгая_синхр.=0.161 сек., средняя=0.067 сек.; расстояние=51821 kB, ожидалось=51821 kB; lsn=4/57100AF0, lsn redo=4/54386730 2024-07-21 09:54:37.149 UTC [1577] СООБЩЕНИЕ: контрольные точки происходят слишком часто (через 3 сек.) 024-07-21 09:54:37.149 UTC [1577] ПОДСКАЗКА: Возможно, стоит увеличить параметр "max_wal_size".
Кроме опции checkpoint_warning для контроля значения max_wal_size, можно еще использовать представление pg_stat_bgwriter.
SELECT checkpoints_timed, checkpoints_req FROM pg_stat_bgwriter;
checkpoints_timed | checkpoints_req
-------------------+-----------------
546 | 78
Здесь checkpoints_timed — количество контрольных точек, которые созданы по таймингу checkpoint_timeout, а checkpoints_req — количество контрольных точек, которые созданы из-за превышения max_wal_size. Первое значение должно со временем увеличиваться, а второе — оставаться постоянным. Если второе значение начало расти — нужно увеличить max_wal_size.
Когда старые файлы журнала WAL оказываются не нужны, они удаляются или перерабатываются (то есть переименовываются для использования в будущем). Если вследствие кратковременного скачка значение max_wal_size превышается — ненужные файлы журнала WAL будут удаляться. Оставаясь ниже этого предела, система перерабатывает столько файлов WAL, сколько необходимо для покрытия ожидаемой потребности и удаляет остальные. Эта оценка базируется на статистике, собранной за предыдущие циклы создания контрольных точек. Но ожидаемая потребность никогда не опускается ниже значения min_wal_size. Рекомендуемое значение min_wal_size — 25% от max_wal_size.
Типы данных
1. Числовые типы
Числовые типы включают двух-, четырёх- и восьмибайтные целые, четырёх- и восьмибайтные числа с плавающей точкой, а также десятичные числа с задаваемой точностью.
| Name | Размер | Описание | Диапазон |
|---|---|---|---|
smallint |
2 байта | целое в небольшом диапазоне | -32768 .. +32767 |
integer |
4 байта | типичный выбор для целых чисел | -2147483648 .. +2147483647 |
bigint |
8 байт | целое в большом диапазоне | -9223372036854775808 .. 9223372036854775807 |
decimal |
переменный | вещественное число с указанной точностью | до 131072 цифр до десятичной точки и до 16383 — после |
numeric |
переменный | вещественное число с указанной точностью | до 131072 цифр до десятичной точки и до 16383 — после |
real |
4 байта | вещественное число с переменной точностью | точность в пределах 6 десятичных цифр |
double precision |
8 байт | вещественное число с переменной точностью | точность в пределах 15 десятичных цифр |
smallserial |
2 байта | небольшое целое с автоувеличением | 1 .. 32767 |
serial |
4 байта | целое с автоувеличением | 1 .. 2147483647 |
bigserial |
8 байт | большое целое с автоувеличением | 1 .. 9223372036854775807 |
2. Символьные типы
Стандарт SQL определяет два основных символьных типа — character varying(n) и character(n), где n — положительное число. Оба эти типа могут хранить текстовые строки длиной до n символов (не байт). Попытка сохранить в столбце такого типа более длинную строку приведёт к ошибке, если только все лишние символы не являются пробелами. Если длина сохраняемой строки оказывается меньше объявленной, значения типа character будут дополнятся пробелами, а тип character varying просто сохранит короткую строку.
Записи varchar(n) и char(n) являются синонимами character varying(n) и character(n) соответственно. Если n задано, оно должно быть больше нуля и меньше или равно 10485760. Записи character без указания длины соответствует character(1). Если же длина не указывается для character varying, этот тип будет принимать строки любого размера. Это поведение является расширением PostgreSQL.
Помимо этого, PostgreSQL предлагает тип text, в котором можно хранить строки произвольной длины. Хотя тип text не описан в стандарте SQL, его поддерживают и некоторые другие СУБД.
| Name | Описание |
|---|---|
character varying(n), varchar(n) |
строка ограниченной переменной длины |
character(n), char(n) |
строка фиксированной длины, дополненная пробелами |
text |
строка неограниченной переменной длины |
3. Типы даты/времени
Все даты считаются по Григорианскому календарю, даже для времени до его введения.
| Name | Размер | Описание | Наименьшее значение | Наибольшее значение | Точность |
|---|---|---|---|---|---|
timestamp [(p)] [without time zone] |
8 байт | дата и время (без часового пояса) | 4713 до н. э. | 294276 н. э. | 1 микросекунда |
timestamp [(p)] with time zone |
8 байт | дата и время (с часовым поясом) | 4713 до н. э. | 294276 н. э. | 1 микросекунда |
date | 4 байта | дата (без времени суток) | 4713 до н. э. | 5874897 н. э. | 1 день |
time [(p)] [without time zone] |
8 байт | время суток (без даты) | 00:00:00 | 24:00:00 | 1 микросекунда |
time [(p)] with time zone |
12 байт | время дня (без даты), с часовым поясом | 00:00:00+1559 | 24:00:00-1559 | 1 микросекунда |
interval [поля] [(p)] |
16 байт | временной интервал | -178000000 лет | 178000000 лет | 1 микросекунда |
4. Логический тип
Тип boolean может иметь состояния «true», «false» и третье — «unknown», которое представляется SQL-значением NULL.
| Наименование | Размер | Описание |
|---|---|---|
boolean |
1 байт | Истина или ложь |
Логические константы могут представляться в SQL-запросах следующими ключевыми словами TRUE, FALSE и NULL.
5. Перечисление
Перечисление (enum) — тип данных, который состоит из статических, упорядоченных списков значений. В отличие от других типов, данный тип должен быть создан при помощи операторв CREATE TYPE.
CREATE TYPE week AS ENUM ('Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun');
6. Последовательность
Sequence (последовательность) — автоматическая уникальная нумерация. Можно создавать вручную или использовать готовый вариант.
Для автоматического создания можно использовать тип serial. По сути, это синтаксический сахар — под капотом это integer 4 байта + NOT NULL + создание последовательности + установка DEFAULT (значение по умолчанию).
CREATE TABLE users ( id serial PRIMARY KEY, username varchar(50) NOT NULL );
CREATE SEQUENCE создаёт генератор последовательности. Эта операция включает создание и инициализацию специальной таблицы имя, содержащей одну строку. Владельцем генератора будет пользователь, выполняющий эту команду.
CREATE SEQUENCE [схема.]имя [OWNED BY таблица.столбец]
Необязательное OWNED BY позволяет связать последовательность с определённым столбцом таблицы так, чтобы при удалении этого столбца (или всей таблицы) последовательность удалялась автоматически. Указанная таблица должна иметь того же владельца и находиться в той же схеме, что и последовательность.
CREATE SEQUENCE user_id_seq; CREATE TABLE users ( id integer PRIMARY KEY DEFAULT nextval('user_id_seq'), username varchar(50) NOT NULL ); ALTER SEQUENCE user_id_seq OWNED BY users.id;
- Redis. Установка и настройка
- Dante. Установка и настройка прокси-сервера
- Установка WireGuard на Ubuntu 20.04 LTS. Часть вторая из двух
- Установка WireGuard на Ubuntu 20.04 LTS. Часть первая из двух
- Установка OpenVPN на Ubuntu 18.04 LTS. Часть 12 из 12
- Установка OpenVPN на Ubuntu 18.04 LTS. Часть 11 из 12
- Установка OpenVPN на Ubuntu 18.04 LTS. Часть 10 из 12
Поиск: База данных • Настройка • Сервер • Клиент • Установка • Конфигурация • PostgreSQL • psql • WAL